Continuation of FTL-queries outgrowing /dev/shm
Expected Behaviour:
Query log should not be allowed to outgrow /dev/shm.
Actual Behaviour:
Query log is allowed to outgrow /dev/shm leading to a FTL crash loop.
Debug Token:
Not able to capture relevant info due to crash loop; must delete pihole-FTL.db to achieve startup which clears the relevant info.
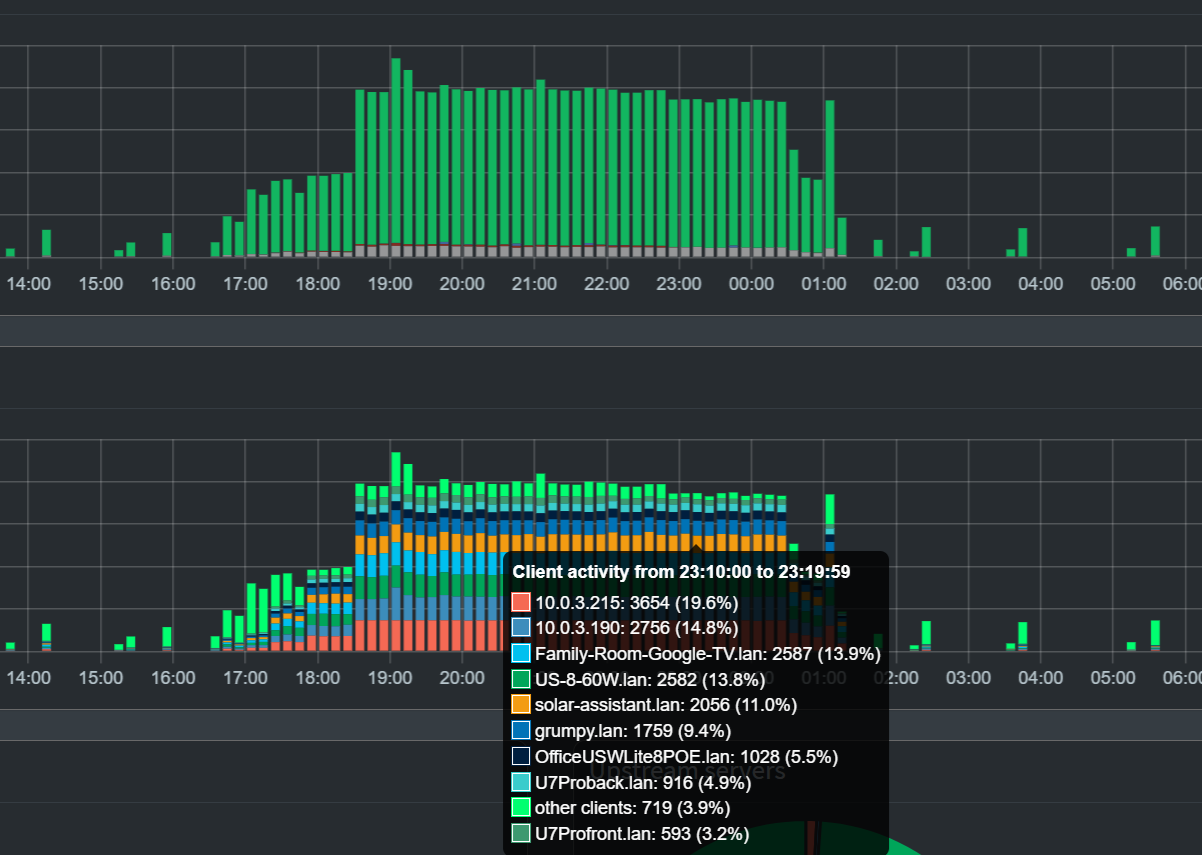
Happened again -- internet was out for a day, devices blasted out DNS queries during the outage and filled up /dev/shm leading to a crash loop. I wasn't able to grab >stats and >top-clients in the midst of the restarts but I was able to get a screen grab. It shows there was no single device or class of devices at fault; it was a broad set of devices (TVs, Chromecasts, network devices, robo vac, solar assistant) sending a big increase in queries.
2025-05-31 09:45:34.590 CDT [49M] INFO: Imported 904906 queries from the long-term database
2025-05-31 09:45:34.591 CDT [49M] INFO: -> Total DNS queries: 904906
...
2025-05-31 09:48:18.162 CDT [49M] WARNING: Shared memory shortage (/dev/shm) ahead: 99% is used (67.1MB used, 67.1MB total, FTL uses 67.1MB)
2025-05-31 09:48:18.166 CDT [49M] WARNING: Could not fallocate() in realloc_shm() (/app/src/shmem.c:838): No space left on device
2025-05-31 09:48:18.166 CDT [49M] CRIT: realloc_shm(): Failed to resize "/FTL-49-queries" (10) to 65470464: No space left on device (28)
In light of this -- WAN outage due to external factors, general device behavior during the outage, no single device to punish for bad behavior -- would some kind of measure to manage /dev/shm proactively to prevent a crash loop be called for?
Thank you for the awesome software.