Hello everyone,
I wanted to show you something I have been sitting on for a while but am finally ready to share.

What you are looking at is a graph on the dashboard that visulizes the response times of forwarded queries in the form of quartiles (median + median of upper half + median of lower half). I decided against simply plotting the mean (aka average), since that is affected too much by outliers and not representative of what the DNS experience feels like.
The dashboard already shows us data about the number of allowed and blocked queries, even on a per device basis. It breaks down all queries in their types as well as the upstream DNS server. We also got information about which domains are hit the most of often, be that allowed or blocked, and also a rundown of which devices are the most active. Showing us a relatively rough visualization about what the response times look like was the last thing missing from a comprehensive overview.
The graph is not hidden behind authentication, it shows up without being logged in just like the total queries graph.
Statistics about the response times do not differentiate between different upstream DNS servers or query types. When using four of Cloudflare's DNS servers, the response time is very consistent. The dips in the middle are where there wasn't much traffic besides Pi-hole's hourly PTR queries, which were send to my FRITZ!Box. These usually take <10 ms and pull the graph down if there isn't any other traffic to overshadow them.

Unbound on the other hand... It's not the fastest or most consistent available DNS server, but it's also not so slow that I would notice during everyday browsing. The graph is here probably more relevant to spot strange delays/outages than when using commercial upstream DNS servers.

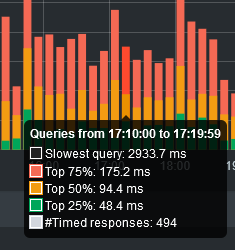
Two close-ups of the tooltip. Displayed are:
- Black: The absolute slowest query within a given interval (not shown in the graph itself)
- Red: Upper quartile (75% of all queries were faster than this value)
- Yellow: Median (50% of all queries were faster than this value)
- Green: Lower quartile (25% of all queries were faster than this value)
- White: The number of timed queries (only forwarded queries with the
response_calculatedflag)(not shown in the graph itself, it's not a time, duh)
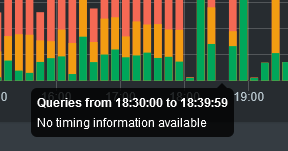
If the number of timed queries is zero, the tooltip will simply say "No timing information available":
The reason why I had been hesitant to create a feature request before is that the response times were never saved to the database and therefore the graph would "break" every restart. Not a huge issue for me, but not something that should plague a final product. But now that FTL#1285 is merged, this won't be an issue in future versions (that said, my code does include a little fix in that regard).
Code for the AdminLTE and FTL repo is here (no changes to the core repo) (PR on demand ![]() ):
):
https://github.com/pi-hole/AdminLTE/compare/devel...Daxtorim:feature/api/response-overTime
https://github.com/pi-hole/FTL/compare/development...Daxtorim:feature/api/response-overTime
Feedback appreciated ![]()