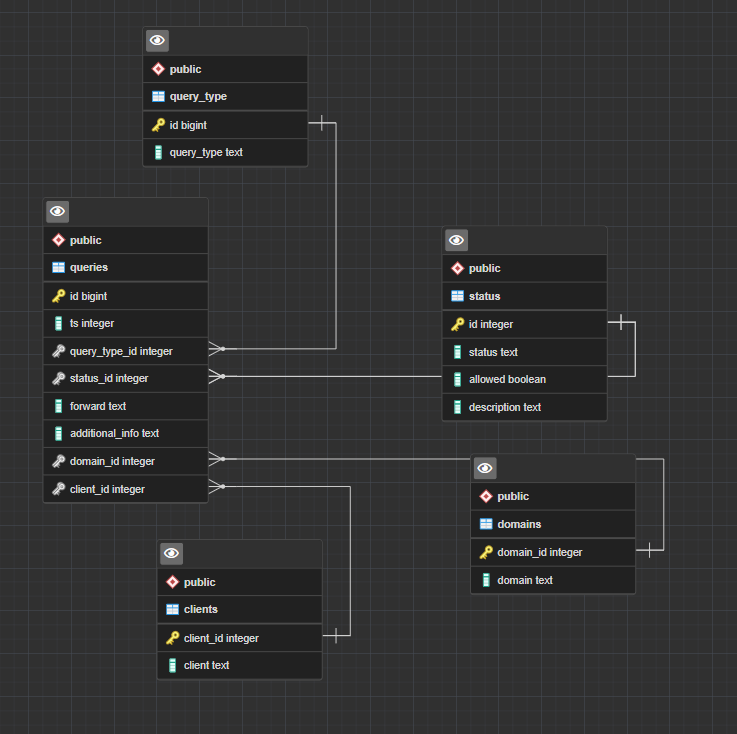
So my limited testing with a smaller dataset, it loosk to only improve things with normalization. Here is my results. Those against history are normalized (its a view) and those against queries are the old version. At the bottom is the SQL I used. This way wouldn'tlock the DB, so it could be run in the background and then verify the new DB before replacing it. I think that addresses any of your concerns? Would just need to run a pargma integrity to verify it before making the final replacement. Anyone want to test on a larger data set? Just make sure to run PRAGMA foreign_keys = ON; to enable the FKs when you open your connection.
This was a simple count(*) but more specific queries will improve even more for sure. The inserts seem more consistent speed wise /w the upsert method. However, unfortunately sqlite doesnt support loops or I'd test with more. Maybe ill write a quick python script to loop it for more detailed testing, but not today 
sudo sqlite3 Test.db ".read test.sql"
sqlite> select count(*) from history where client = '192.168.2.155';
71509
Run Time: real 1.039 user 1.007407 sys 0.030865
sqlite> select count(*) from history where client = '192.168.2.155';
71509
Run Time: real 1.038 user 0.948123 sys 0.089802
sqlite> select count(*) from history where client = '192.168.2.155';
71509
Run Time: real 1.031 user 0.989952 sys 0.040031
sqlite> select count(*) from history where client = '192.168.2.155';
71509
Run Time: real 1.036 user 0.965032 sys 0.070296
sqlite> select count(*) from history where client = '192.168.2.155';
71509
Run Time: real 1.035 user 1.004284 sys 0.029671
sqlite> select count(*) from history where client = '192.168.2.155';
71509
Run Time: real 1.035 user 0.994221 sys 0.039705
sqlite>
sqlite> insert into history (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from history limit 10000;
Run Time: real 1.063 user 0.682191 sys 0.030671
sqlite> insert into history (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from history limit 10000;
Run Time: real 1.244 user 0.719878 sys 0.009267
sqlite> insert into history (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from history limit 10000;
Run Time: real 1.571 user 0.739281 sys 0.000249
sqlite> insert into history (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from history limit 10000;
Run Time: real 1.795 user 0.730746 sys 0.010223
sqlite> insert into history (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from history limit 10000;
Run Time: real 4.090 user 0.728491 sys 0.029757
sqlite> insert into history (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from history limit 10000;
Run Time: real 3.619 user 0.734049 sys 0.020111
sqlite> insert into history (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from history limit 10000;
Run Time: real 3.239 user 0.726018 sys 0.020167
sqlite> insert into history (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from history limit 10000;
Run Time: real 1.946 user 0.738246 sys 0.019949
sqlite> select count(*) from queries where client = '192.168.2.155';
71509
Run Time: real 1.268 user 1.106239 sys 0.160775
sqlite> select count(*) from queries where client = '192.168.2.155';
71509
Run Time: real 1.281 user 1.199737 sys 0.079670
sqlite> select count(*) from queries where client = '192.168.2.155';
71509
Run Time: real 1.259 user 1.118651 sys 0.139912
sqlite> select count(*) from queries where client = '192.168.2.155';
71509
Run Time: real 1.286 user 1.125245 sys 0.159506
sqlite> select count(*) from queries where client = '192.168.2.155';
71509
Run Time: real 1.286 user 1.064541 sys 0.220703
sqlite>
sqlite> ^Cinsert into queries (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_in from queries limit 10000;
Run Time: real 6.939 user 0.186649 sys 0.054963
sqlite> insert into queries (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from queries limit 10000;
Run Time: real 3.648 user 0.173676 sys 0.081017
sqlite> insert into queries (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from queries limit 10000;
Run Time: real 2.111 user 0.194485 sys 0.060911
sqlite> insert into queries (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from queries limit 10000;
Run Time: real 7.550 user 0.158069 sys 0.090163
sqlite> insert into queries (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from queries limit 10000;
Run Time: real 2.391 user 0.195867 sys 0.054545
sqlite> insert into queries (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from queries limit 10000;
Run Time: real 2.515 user 0.224625 sys 0.044268
sqlite> insert into queries (timestamp, type, status, domain, client, forward, additional_info) select timestamp, type, status, domain, client, forward, additional_info from queries limit 10000;
Run Time: real 4.307 user 0.159630 sys 0.109274
ATTACH DATABASE 'pihole-FTL.db' AS og;
CREATE TABLE client (id INTEGER PRIMARY KEY AUTOINCREMENT, client text, CONSTRAINT uq_client UNIQUE (client));
CREATE TABLE domain (id INTEGER PRIMARY KEY AUTOINCREMENT, domain text, CONSTRAINT uq_domain UNIQUE (domain));
CREATE TABLE forward (id INTEGER PRIMARY KEY AUTOINCREMENT, forward text not null default "", CONSTRAINT uq_forward UNIQUE (forward));
CREATE TABLE queries ( id INTEGER PRIMARY KEY AUTOINCREMENT, timestamp INTEGER NOT NULL, type INTEGER NOT NULL, status INTEGER NOT NULL, domain_id INTEGER , client_id INTEGER , forward_id INTEGER , additional_info TEXT, FOREIGN KEY(client_id) REFERENCES client(id)
, FOREIGN KEY(domain_id) REFERENCES domain(id)
, FOREIGN KEY(forward_id) REFERENCES forward(id));
CREATE INDEX idx_queries_timestamps ON queries (TIMESTAMP);
CREATE TABLE aliasclient (id INTEGER PRIMARY KEY NOT NULL, name TEXT NOT NULL, comment TEXT);
CREATE TABLE counters ( id INTEGER PRIMARY KEY NOT NULL, value INTEGER NOT NULL );
CREATE TABLE ftl ( id INTEGER PRIMARY KEY NOT NULL, value BLOB NOT NULL );
CREATE TABLE message ( id INTEGER PRIMARY KEY AUTOINCREMENT, timestamp INTEGER NOT NULL, type TEXT NOT NULL, message TEXT NOT NULL, blob1 BLOB, blob2 BLOB, blob3 BLOB, blob4 BLOB, blob5 BLOB );
CREATE TABLE network_addresses ( network_id INTEGER NOT NULL, ip TEXT UNIQUE NOT NULL, lastSeen INTEGER NOT NULL DEFAULT (cast(strftime('%s', 'now') as int)), name TEXT, nameUpdated INTEGER, FOREIGN KEY(network_id) REFERENCES network(id));
INSERT INTO client (client) select distinct client from og.queries;
INSERT INTO domain (domain) select distinct domain from og.queries;
INSERT INTO forward (forward) select distinct ifnull(forward,"") from og.queries;
INSERT INTO queries (id, timestamp, type, status, domain_id, client_id, forward_id, additional_info)
select id, timestamp, type, status, (select id from domain where domain = queries.domain), (select id from client where client = queries.client)
,(select id from forward where ifnull(forward,"") = ifnull(queries.forward,"")), additional_info
from og.queries;
create view history (id, timestamp, type, status, domain, client, forward, additional_info)
as
select
q.id, q.timestamp, q.type, q.status, d.domain, c.client, f.forward, q.additional_info
from queries q join domain d on q.domain_id = d.id join client c on q.client_id = c.id join forward f on q.forward_id = f.id ;
CREATE TRIGGER trig1
INSTEAD OF INSERT ON history
BEGIN
INSERT INTO client (client)
VALUES (NEW.client) ON CONFLICT (client) DO NOTHING;
INSERT INTO domain (domain)
VALUES (NEW.domain) ON CONFLICT (domain) DO NOTHING;
INSERT INTO forward (forward)
VALUES (NEW.forward) ON CONFLICT (forward) DO NOTHING;
insert into queries (timestamp, type, status, domain_id, client_id, forward_id, additional_info)
select NEW.timestamp, NEW.type, NEW.status, (SELECT id from domain where domain = NEW.domain), (SELECT id from client where client = NEW.client), (SELECT id from forward where forward = NEW.forward), NEW.additional_info
;
END;