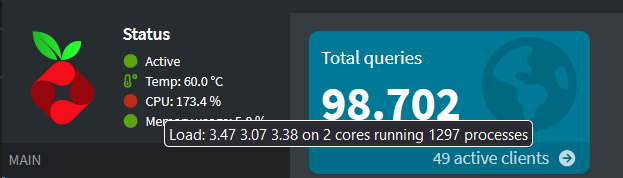
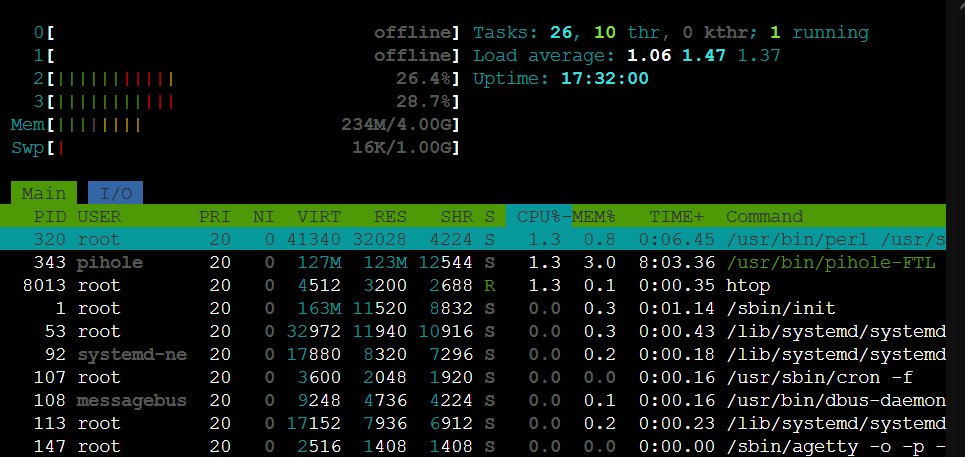
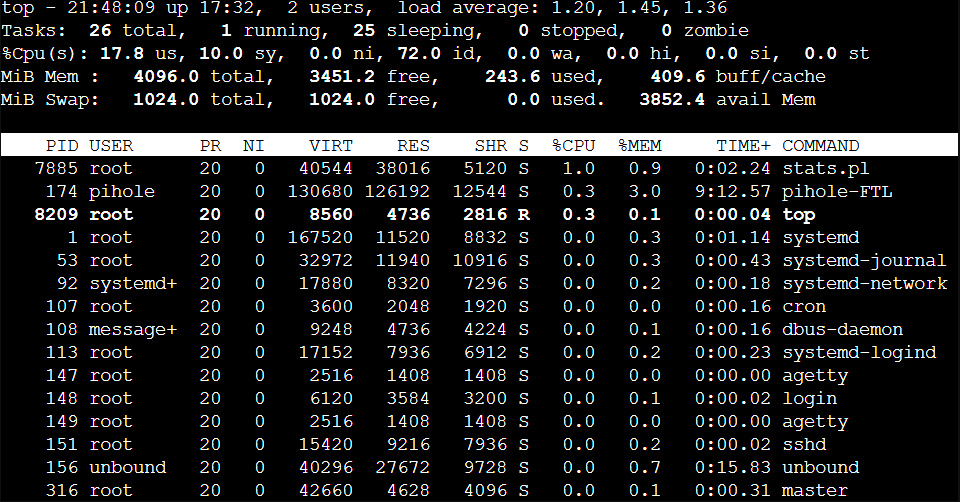
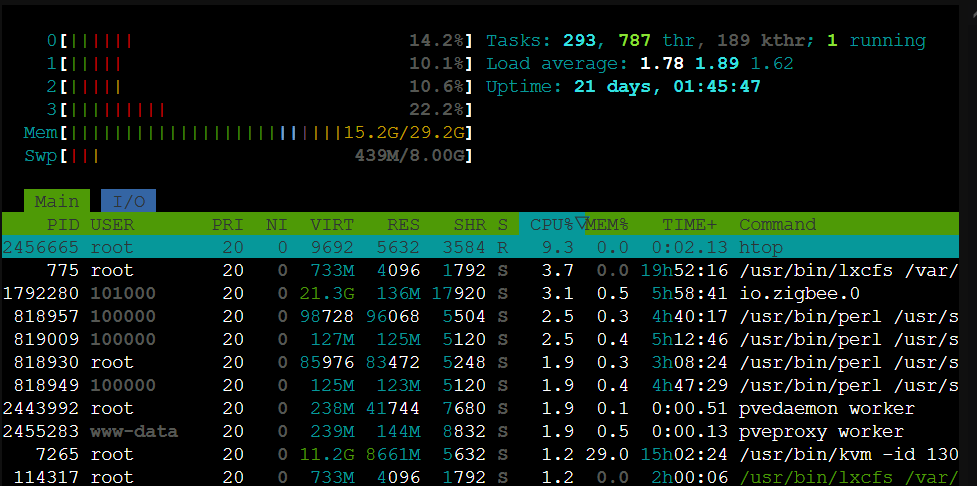
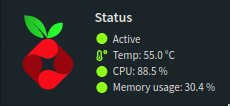
As seen there is a calculation mismatch and it goes over 100%. If checking at several othre toos like Webmin or console at proxmox all is fine and right
$ man proc
[..]
/proc/loadavg
The first three fields in this file are load average figures
giving the number of jobs in the run queue (state R) or waiting
for disk I/O (state D) averaged over 1, 5, and 15 minutes. They
are the same as the load average numbers given by uptime(1) and
other programs. The fourth field consists of two numbers sepa-
rated by a slash (/). The first of these is the number of cur-
rently runnable kernel scheduling entities (processes, threads).
The value after the slash is the number of kernel scheduling en-
tities that currently exist on the system. The fifth field is
the PID of the process that was most recently created on the
system.
$ man uptime
[..]
... Load averages
are not normalized for the number of CPUs in a system, so a load aver-
age of 1 means a single CPU system is loaded all the time while on a 4
CPU system it means it was idle 75% of the time.
So a load average of two on a two CPU/core system is still healthy.
A load average of 3.47 on a two CPU system like in your case is unhealthy.
EDIT: For below system of mine, a load average above three would be unhealthy:
Then the question arises why the display in the visualized interface of the lxc container is at max 3-5% under proxmox and also under webmin. In addition, the system is ultra fast and has no lags
Seen where? What do the "other tools" show precisely? It'd be helpful if you could provide some more screenshots.
Pi-hole uses a similar algorithm to compute the CPU utilization as do popular tools like htop. The only difference is that we do not cap the CPU at 100% but show if the value exceeds this kind of artificial threshold. Any value > 100% simply means that your CPU isn't able to do everything in time and stuff is queued to be processed later. This has a number of bad consequences and, hence, we thought you as the user might want to know about this.
I guess the error is in proxmox telling the Pi-hole container the load of the entire host but then announce only two cores being available to process this load. If the underlying virtualization host is providing incorrect data (an assumption so far), how could Pi-hole show the right numbers? If Proxmox shows
then it's probably telling the container wrong numbers.
Please - if you compare with other tools - do it inside the same VM your Pi-hole is running in. Otherwise, such tools know "more" and the comparison is unfair. If it turns out that this is indeed a Pi-hole - and not a virtualizer - bug, we will of course be more than happy to fix this.
Let's begin with looking at the output of top (only the header), uptime and htop. And this once on the host and once inside your virtual machine. That should give us a good start.
Okay, so the system is reporting the entire system's load inside the container - there is no way the container itself can find out its own CPU load. Likewise, your htop screenshots show what the container sees two cores are around 25% each while the only process using noteworthy CPU% is perl, pihole-FTL and htop merely contributing to like 4% (instead of 26.4 + 28.7 = 55.1%).
What is missing here is a screenshot of the web interface but I guess it will have shown something between 1.06/2 = 53% and 1.51/2 = 75% at that time. We could indeed change this to use the number of available (nproc --all = 4) instead of configured (nproc = 2) so the shown percentages would have been between 26% and 32% matching what we see in your htop (27.5%) and top (17.8 + 10.0 = 28.8%) screenshots.
FWIW, that the container does not know its "own" load but also sees the entire host's load seems to be an LXC bug and one that will not go away soon, too. It is the same for docker which does make sense.
Please run
pihole checkout ftl tweak/nprocs_conf
and check if the CPU percentage is now what you'd expect. But please keep in mind that the CPU utilization inside LXC containers will be the same as on the host system due to the aforementioned LXC bug.
It has changed, but due to the bug in LXC I guess I'll just ignore the display because the system is healthy and fast.
Maybe you can implement a configuration option in the web interface to display the value or not?
Is it still higher than on the host even on the custom branch you switched to? It's clear that it is higher than the particular container's actual CPU load as we discussed above.
Just an idea here ...
I spun up my old device running pihole v5 (while compiling v6 on the newer one) and noticed that in v5 we did not have CPU usage, we had load instead. I don't really care about these statistics, but since they are causing some confusion ... what about showing the load, instead of CPU usage?
Load and CPU % are basically the same thing, for those not grown up with Linux, a percentage just seems to feel somewhat more intuitive due to everyday experiences with percentage values. A load of 3.0 means 75% on a 4 core system and everything will be fine. On a two core, system, however, it already means overbooking (~ 150%) and some stuff has to wait.
In the end, this LXC bug is actually not too bad because seeing the host's load is actually a much more useful metric than the virtualized containers load.
Some thoughts on this: Sure, it may happen that you have allocated too few cores and your container has to wait because of that, but that's rather unlikely with Pi-hole as it can typically run fine with only one core (even when that surely not recommended because you are losing all the multiprocessing benefits). However, the other way around (the host hosting possibly many containers is super busy while the Pi-hole container doesn't have much load at all) is much more often the case. And when the host can't cope with the load the container will obviously feel slow downs as well even when the CPU utilization inside the container is almost 0%.