I was gobsmacked by incredibly large pihole.log file growth in an extremely short time period. Hours, not days or weeks to grow the main log to >15GB.
I dusted off my coding skillz from a previous life, and wrote some automation to import pihole.log files into SQL Server. WinSCP, PowerShell, BCP, and a SQL 2022 developer edition instance running on a VM running Ubuntu 22.04.
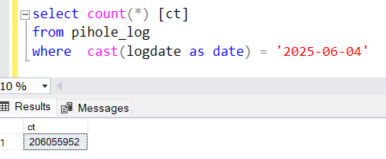
Processed the whole shebang in less than an hour (mind you, it was hundreds of millions of records).
If anyone is interested in the implementation details, let mw know. I'm happy to share the code.
ETL'g the data to my db instance means I can keep it longer if I wish, and I can do more in-depth analysis than I think I can do in SQLite
I am concerned about the cost of querying the db live while it is getting hammered by a rogue process. I would not want my queries to be the reason that my little raspi locks up
Thanks for the link! I'll read up and figure out what I want to do next...