Some services are polling several times in a minute. All these entries are showing up in the Query Log. There should be an option to hide or ignore/exclude domains from the Query Log viewer.
How about hiding the domains that is in the exclude list (left input box) also in the Query Log?

I assume that users exclude domains in there that are queries most often and which should then also be hidden on the
Query Log?
In contrast to an additional list, implementing it as I suggest will be less than ten minutes of work.
Nice, option to exclude domains from Query log page would be great!
This feature will help to hide commonly appearing domains and some blacklisted domains contacting several thousand times a day (like Amazon metrics, some NTP domains, and littlefield.logs.roku )
And also it helps in the analysis of large number of queries. What do you think @DL6ER?
1 Like
I second this also. Hiding them from the query list will be great !
I'm flooded by localhost queries every time i access the query log.
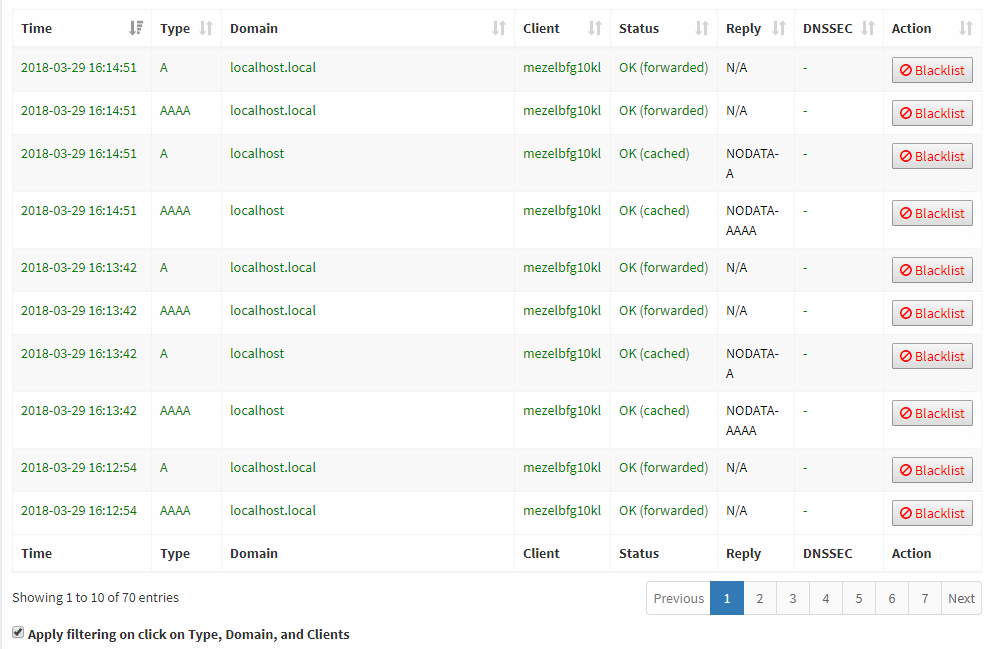
Is it something i can change within the code (use the same top list from the api option) and have those entries ignored and not displayed in the wuery log?
At least for localhost, there is already a feature for this in FTLDNS:
1 Like
This only prevents hits TO localhost, right?
It will not ignore legitimate hits to different hosts, originating from localhost
As in, localhost querying github will still show, right?
No, see the description of this config option:
IGNORE_LOCALHOST=no|yes(ShouldFTLignore queries coming from the local machine?)
It's a good feature however, I personally would still like to see if locahost is "dialing" out and where EXCEPT for self queries.
It would be just a cosmetic thing I agree.
What I was thinking about is an approach like the API/Web Interface Exclude options.
Not only in the Top lists but also Query log.
So if a query is placed to localhost and/or localhost.local, or any domain specified in the Exclude Boxes, strip it from being displayed ...
I see, but, unfortunately, there is a (significant!) performance penalty connected to this feature which is the sole reason for why we have not added it yet. Assume we have 15 clients on a typical system with 20.000 queries within 24 hours. Then, the filter would have to be applied 15*20.000 = 300.000 times as we would have to check in each and every query for each and every domain individually if we want to show them or not. Not even going to mention how wildcard comparisons might perform (they are much more costly in terms of computations time). Sure, there are ways to code around this like using tree methods and similar techniques, but this would make the code still slower (albeit not as dramatic) but also much harder to maintain).
1 Like
If you enable ssh to your pi-hole, you can tail -f the log file and run that through whatever you like. I detail doing that here for a roku, but it is more or less the same for any device.
@DL6ER what about ignoring the entire client itself other than localhost? For example, IGNORE_CLIENT=10.0.0.13 does it affect any performance?
1 Like
If we add it now, users will want to have an arbitrary long list of clients to be ignored in the future. It would have a notable performance penalty as each entry in the entire Query Log would have to be matched against each of the clients to be ignored. Whilst possible, this would surely have a bad influence.
We're (internally) working on a new API implementation. This API will provide the Query Log of the future and may be able to handle this better. As it will also support pagination, it would have to check against a significantly lower number of queries on each individual request reducing the performance penalty notably.
2 Likes
I agree. I don't mind as much if they are still stored in the logs under the hood, but it would be nice to be able to filter items out on the Query Log in the web client. Bonus points if you can make the block stats do the same.
I see, but, unfortunately, there is a (significant!) performance penalty connected to this feature which is the sole reason for why we have not added it yet. Assume we have 15 clients on a typical system with 20.000 queries within 24 hours. Then, the filter would have to be applied 15*20.000 = 300.000 times as we would have to check in each and every query for each and every domain individually if we want to show them or not.
There's no need to check each domain individually (excluding wildcard functionality). Searching a Hashset of excluded domains would be trivially fast, assuming users don't put 50k domains in.
Another option would be to maintain a separate "filtered" bit and set it appropriately when the request is serviced. If the user changes the filters, reprocess all requests and reset the bits appropriately. This would remove the need to do the filtering on the web client.
The issue is not how long it takes to figure out if one query should be filtered out or not, it's that we have to check each query. It takes O(1) to check a hash set (theoretically), but since you do that N times it takes O(n).
As @DL6ER noted, we are solving these filtering questions in the API, where it is easier to use things like hash sets.
Yes, the additional filter check would add O(n) to request processing, but that process must already be at least O(n). You would be adding 1 to the multiplier.
Or is the problem that Hashsets aren't available at the level where the web interface would be doing the filtering?
The web interface does not do the filtering, that currently happens in FTL. Because FTL is in C, it does not have many nice things like hash maps or hash sets built in. The API is in Rust, which does have those features as part of the standard library. For FTL to do this level of filtering, it would either need to implement a hash set/map (complex, not fun) or use a slower approach with an array (fastest reasonable approach would be binary search, O(n log n) to filter all of the queries). There can be hundreds of thousands of queries, so we want to keep filtering performant.
2 Likes
any news here?
or its already implemened? how i can exclude domains from querylog (to see better the other domains)
1 Like
There are two complimentary requests regarding not logging certain resolutions to queries table: this one about ignoring certain domains and another about ignoring certain clients.
Pi-Hole already knows how to very efficiently decide what to do with requests based on the set of rules. It would be amazing to be able to also define what it should do with logging based on a similar set of rules (e.g. client's group, domain, decision to block or allow etc). It should cover both requests very nicely.
In my particular situation I have a Chinese IoT that tries to access baidu.com every couple of seconds. It is always blocked but it does not prevent anything, and the FTL database grows several hundred thousands records every week. Deleting them manually and truncating statistics is very boring to say the least...
2 Likes