Pihole + Wireguard running smoothly (has been this way for months) on a VPS running Ubuntu 18.04.
Apart from Syncthing, nothing else is installed on the server. All the packages are up to date.
Actual Behaviour:
DNS has been failing every day at 10.30AM and 10.30PM, for a week now.
Can't SSH into the server once it happens. I have to go to the VPS provider (OVH) interface, reboot the server and sudo service pihole-FTL restart to get everything back, for another 12 hours.
Nothing has changed, I had not touched my setup for months, excepted updating Ubuntu packages every now and then.
In fact I first lost Internet Friday evening while I was reading about Cloudflare issues. At first I thought it was related, then I remembered that I was running only Unbound. I rebooted and relaunched pihole-FTL, then it happened Saturday morning and haven't stopped since.
And I suspected the network issue, too. But how come that it needs (1) a reboot and (2) a pihole-FTL restart to get back on its feet?
Last, the long term DB is disabled on purpose. It was a recommendation from someone from the team (either here or on Reddit, can't recall) as the size of the database was growing out of control (I have at least 15GB free on the server and couldn't understand how it could be the issue but well, it solved my issue at that time, so...).
Just for completeness:
Your debug log shows you are also running unbound and containerd, and your logs also confirm that you are using unbound as Pi-hole's upstream. I hope you intend to use these and just forgot to mention them.
You've also heavily altered Pi-hole's web server - neither dashboard nor block page show Pi-hole's default headers, and it would seem you did so in order to make it accessible via HTTPS only.
I guess this is due to you running Pi-hole in the cloud on a Virtual Private Server (as you mentioned).
I thus would assume that access to your Pi-hole is always through a Wireguard VPN tunnel (in which case you wouldn't need HTTPS on top of that, as long as your VPS blocks access to port 80 for the public). Since you cannot ssh into your VPS at all when an outage occurs for you, have you considered whether Wireguard could be failing?
I noticed that there are some SSL certificate errors in lighttpd's error log:
*** [ DIAGNOSING ]: contents of /var/log/lighttpd
-rw-r--r-- 1 www-data www-data 236488 Jul 23 12:24 2020-07-19 09:40:05: (network.c.145) SSL: no certificate/private key for TLS server name <IP redacted>
2020-07-19 09:40:05: (connections-glue.c.200) SSL: 1 error:1422E0EA:SSL routines:final_server_name:callback failed
I am not sure whether this is signifcant for your situation, as it occurs a bit before your 10:30 window, and the debug log shows only a few lines of that log anyway.
But as you do observe outages at a certain time repeatedly, you should try to correlate the logs of all of your applications for that time.
It may also be worth to consult resources for your additonal software for support.
A thought: Does your VPS run with a static public IP, or do you access it by public hostname that may resolve to different somewhat arbitrary IPs over time? Why and when would those IPs normally change?
Your debug log shows you are also running unbound and containerd, and your logs also confirm that you are using unbound as Pi-hole's upstream. I hope you intend to use these and just forgot to mention them.
But yes, I'm intentionally using unbound as Pi-hole's upstream. But... containerd ? What is that ???
You've also heavily altered Pi-hole's web server - neither dashboard nor block page show Pi-hole's default headers, and it would seem you did so in order to make it accessible via HTTPS only.
I guess this is due to you running Pi-hole in the cloud on a Virtual Private Server (as you mentioned).
I thus would assume that access to your Pi-hole is always through a Wireguard VPN tunnel (in which case you wouldn't need HTTPS on top of that, as long as your VPS blocks access to port 80 for the public). Since you cannot ssh into your VPS at all when an outage occurs for you, have you considered whether Wireguard could be failing?
Yes, I wanted to access the dashboard through a subdomain of mine, and make it the most secure possible. And yes, it was through SSL and requires HTTP authentication. Maybe overkill, but I'm a self-taught guy and discovering all these things with doing, trials and errors. So I might not be exactly aware of when there's an overlap in terms of security or so.
Nice idea, I'll try to find where Wireguard logs are on the system and look into it.
Lastly, my VPS has a static IP, it has never changed and will probably not (it's part of the contract). And I access it through that IP, not a hostname.
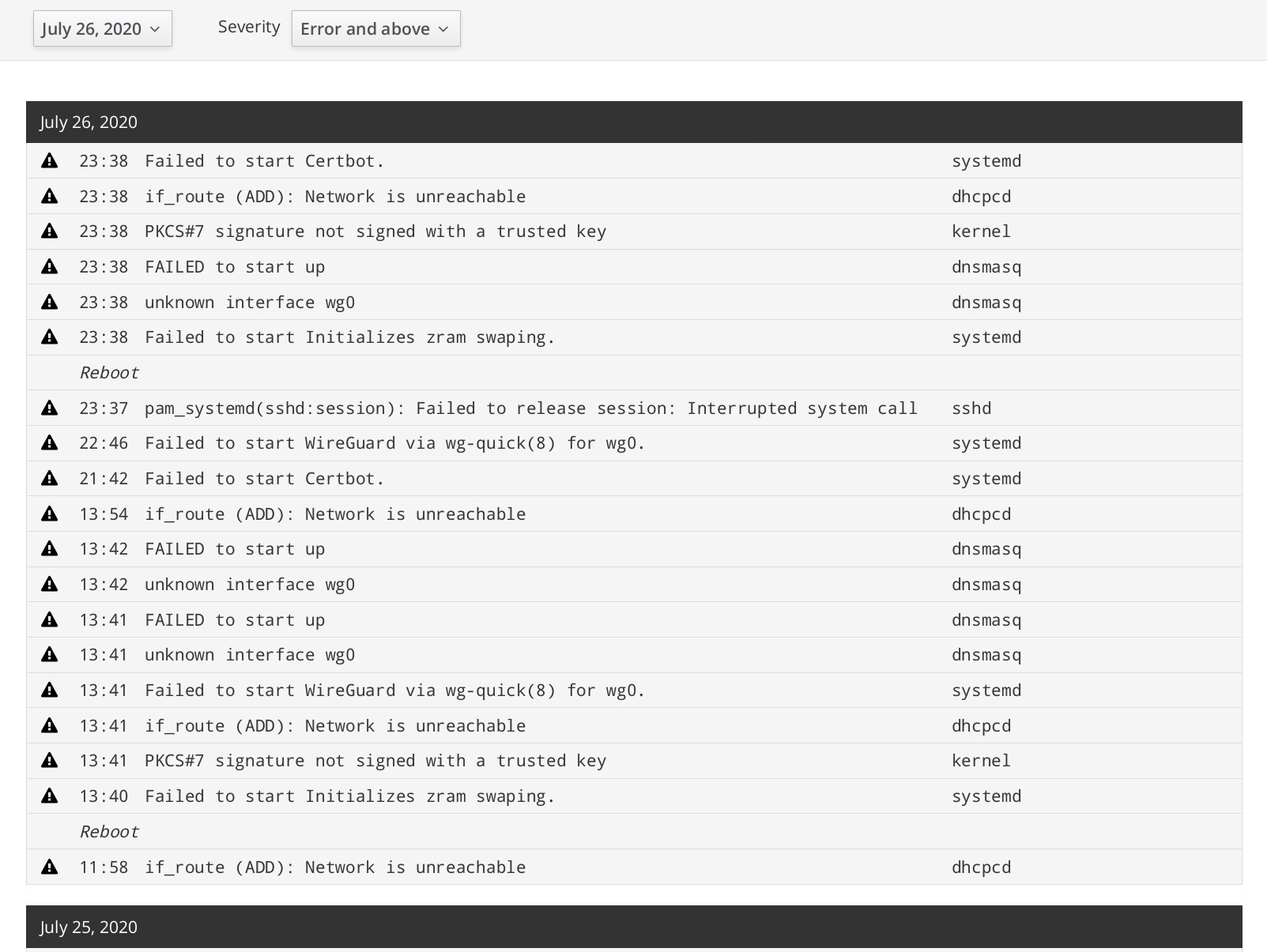
Side note: The outage has occurred again this morning (around 45mn later than usual), and since doing my usual procedure to get it back, I've been going through /var/log/syslog to see if I can get a hint there.
I thought you might have triggered the reload manually.... This could be a hint. There are many debug flags you could enable, but as we don't know what to look for, enabling all debug output might be overkill and fill up your logs extremely fast...
I've spent my Sunday tracking the issue, going from Pihole to Wireguard and back: the system journal shows that dnsmasq fails to start on boot. IIRC the equivalent is pihole-FTL, that's probably why almost everything runs fine again once it restarts.
So now I have to figure out:
why dnsmasq suddenly doesn't start on boot anymore, after running fine for months
Yes, I'm aware of that. My VPS run only Ubuntu 18.04 + Pihole + Wireguard + Syncthing. Nothing else has been installed on / modified in the system, I'm don't have enough knowledge for that.
The thing is, I had this issue on a previous attempt to install Pihole + Wireguard, so when reinstalling the whole VPS, I made sure I didn't install dnsmasq. After your reply and to my surprise, apt list shows me
Maybe related to some sort of automated OS updates for your VPS server?
Try to find out about your VPS provider's update policy for your OS, and how that would relate to dnsmasq explicitly.
Yeah I thought of it, but this is not the case. OS updates are up to the user, and the next one (20.04) will probably be up in a few weeks, when 20.04.1 is out.